MetaDiffuser: Diffusion Model as Conditional Planner for Offline Meta-RL
-
 Paper
Paper
-
 Code
Code
Abstract
Recently, diffusion model shines as a promising backbone for the sequence modeling paradigm in offline reinforcement learning. However, these works mostly lack the generalization ability across tasks with reward or dynamics change. To tackle this challenge, in this paper we propose a task-oriented conditioned diffusion planner for offline meta-RL(MetaDiffuser), which considers the generalization problem as conditional trajectory generation task with contextual representation. The key is to learn a context conditioned diffusion model which can generate task-oriented trajectories for planning across diverse tasks. To enhance the dynamics consistency of the generated trajectories while encouraging trajectories to achieve high returns, we further design a dual-guided module in the sampling process of the diffusion model. The proposed framework enjoys the robustness to the quality of collected warm-start data from the testing task and the flexibility to incorporate with different task representation method. The experiment results on MuJoCo benchmarks show that MetaDiffuser outperforms other strong offline meta-RL baselines, demonstrating the outstanding conditional generation ability of diffusion architecture.
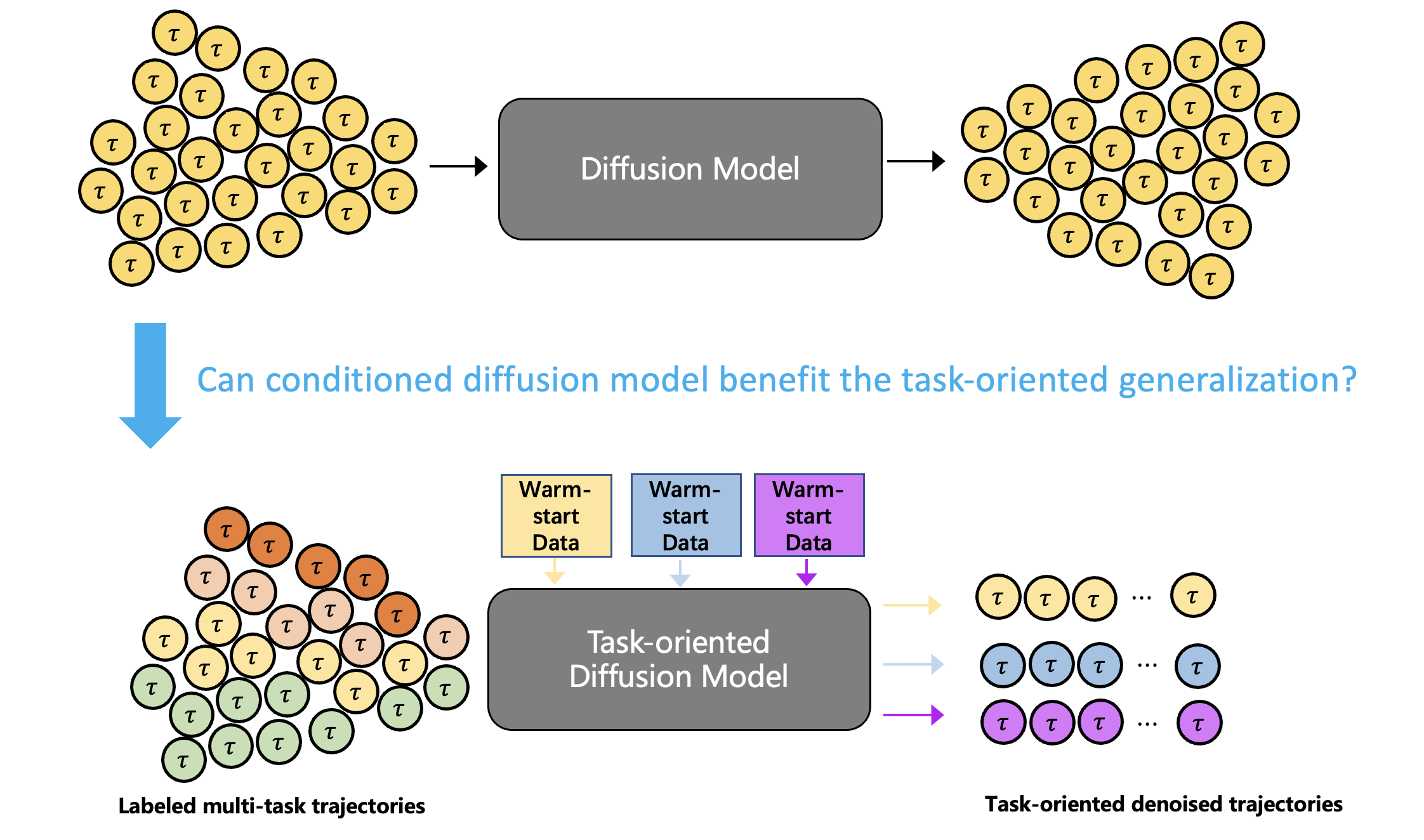
Motivation overview of MetaDiffuser. It enables diffusion models to generate rich synthetic expert data using guidance from reward gradients of either seen or unseen goal-conditioned tasks. Then, it iteratively selects high-quality data via a discriminator to finetune the diffusion model for self-evolving, leading to improved performance on seen tasks and better generalizability to unseen tasks.
Planning with diffusion model (Janner et al., 2022b) provides a promising paradigm for offline RL, which utilizes
diffusion model as a trajectory generator by joint diffusing the states and actions from the noise to formulate the
sequence decision-making problem as standard generative
modeling.
Framework of MetaDiffuser
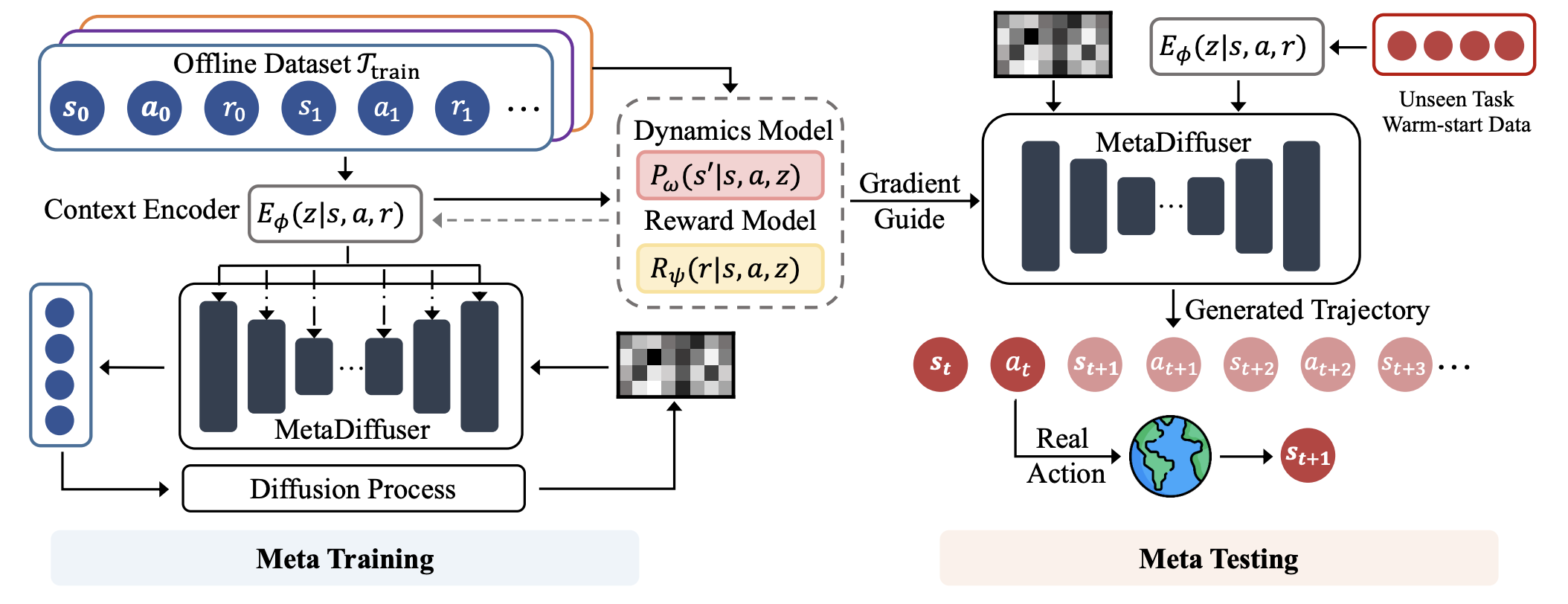
The overview of MetaDiffuser. During meta-training phase, a task-oriented context encoder is trained jointly with conditioned dynamics model and reward model in a self-supervised manner to infer the current task from the recent historical transitions. Then, the multi-task trajectories can be labeled with the trained context encoder and the inferred context are injected in the conditioned diffusion model to estimating the multi-modal distribution mixed by different training tasks. During meta-testing phase, context encoder can capture the task information from provided warm-start data from the test task. Then the conditioned diffusion model can manipulate the noise model to denoise out desired trajectories for the test task with the inferred context. Additionally, the pretrained dynamics model and reward model can serve as classifiers for evaluation, with gradient to guide the conditional generation in a classifier-guide fashion.
Dual guide in the Trajectory Generation
Previous work (Janner et al., 2022a) trains an extra reward predictor to evaluate the accumulative return of generated trajectories and utilizes the gradient of return as a guidance in the sampling process of diffusion model, to encourage the generated trajectories to achieve high return. However, during meta-testing for unseen tasks, the conditional generated trajectories may not always obey dynamics constraints due to the aggressive guidance aim for high return, making it difficult for the planner to follow the expected trajectories during the interaction with the environment. Therefore, we propose a dual-guide to enhance the dynamics consistency of generated trajectories while encouraging the high return simultaneously.
Generated Trajectories.
Real Trajecories.
Generated Trajectories.
Real Trajecories.
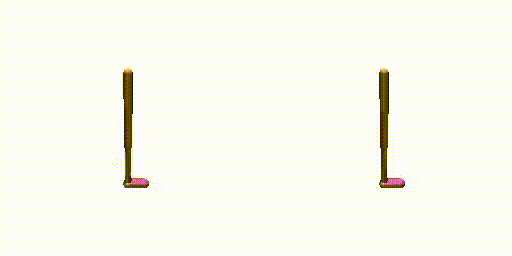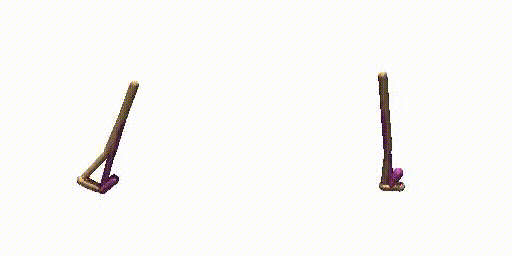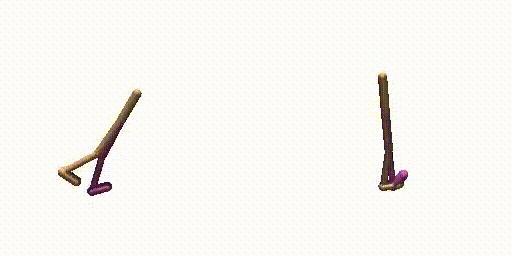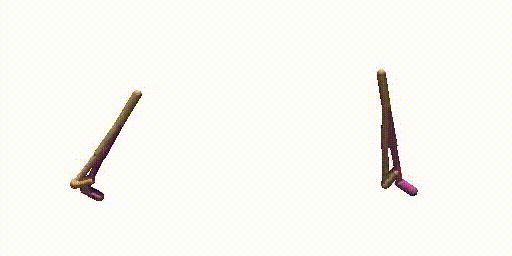
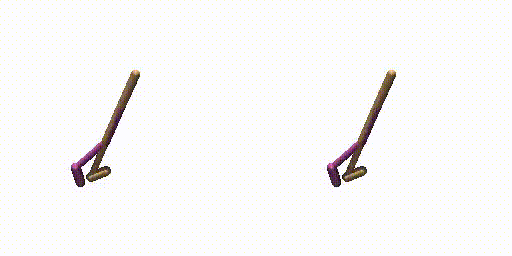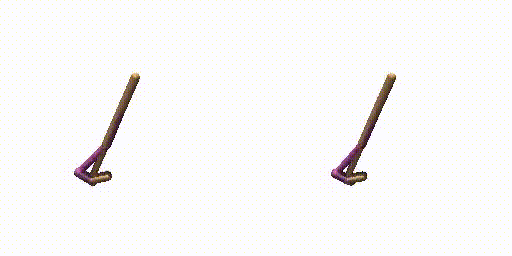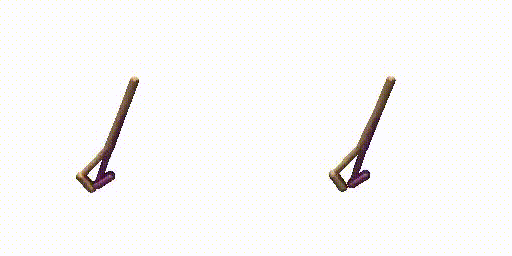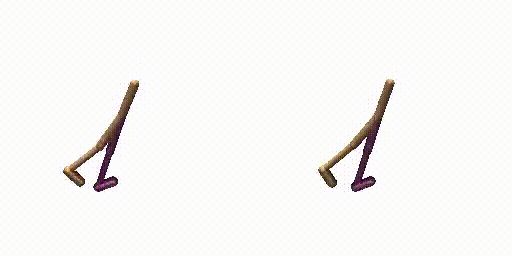
Walker-Params without dual-guide.
Walker-Params with dual-guide.
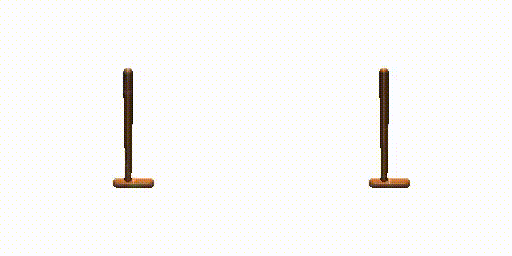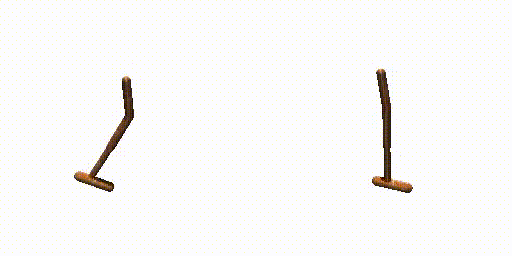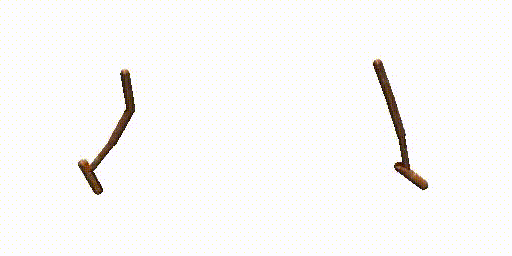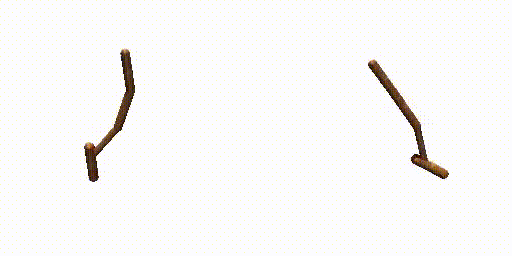
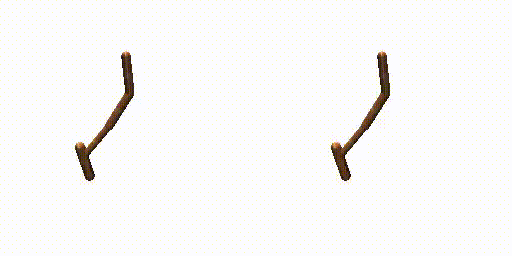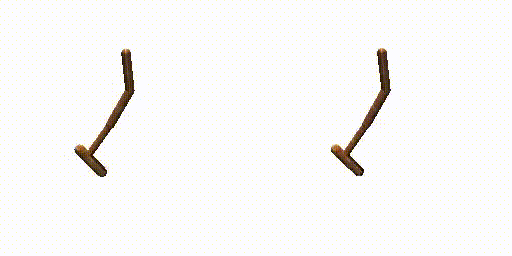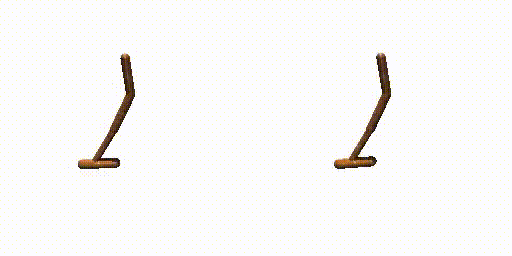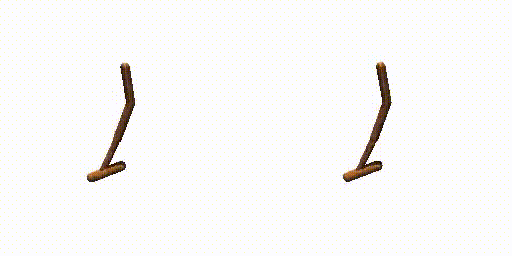
Hopper-Params without dual-guide.
Hopper-Params with dual-guide.
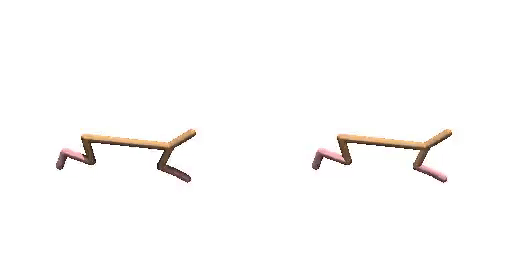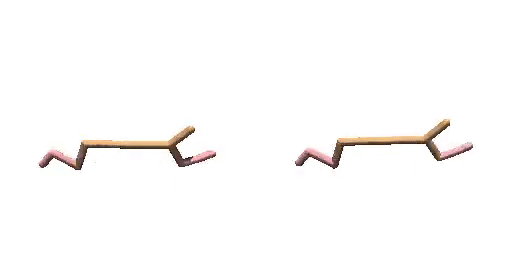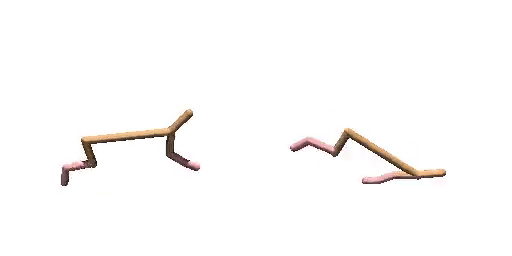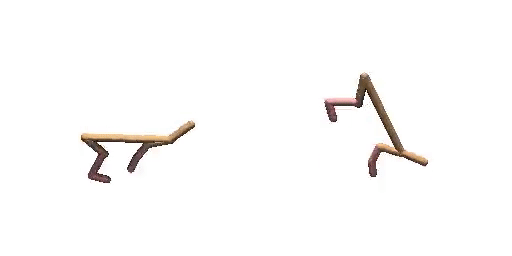
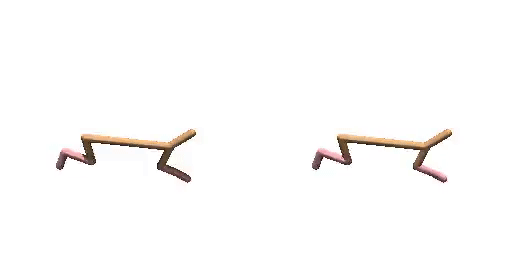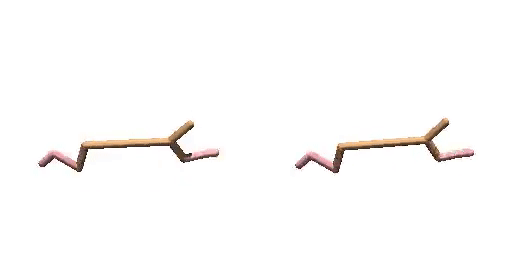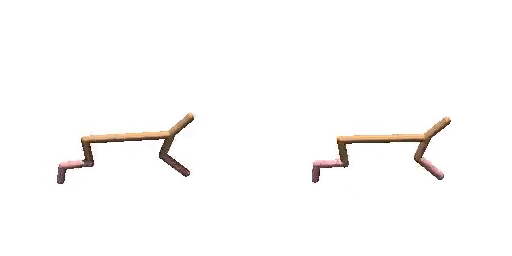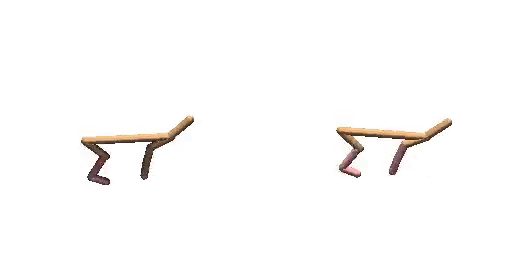
Cheetah-Vel without dual-guide.
Cheetah-Vel with dual-guide.